Term: Infrastructure Stack
The term Infrastructure Stack is something I’ve found useful to explain different patterns for organizing infrastructure code. An infrastructure stack is a collection of infrastructure elements defined and changed as a unit. Stacks are typically managed by tools such as Hashicorp Terraform, AWS CloudFormation, Azure Resource Manager Templates, Google Cloud Deployment Manager Templates and OpenStack Heat.
AWS CloudFormation uses the term “stack” formally, but it maps to other tools as well. When using Terraform, which I tend to use for code examples, a stack correlates to a Terraform project, and a statefile.
Stack definitions
A stack definition is the code that declares what a stack should be. It is a Terraform project, CloudFormation template, and so on. A stack definition may use shared infrastructure code - for example, CloudFormation nested stacks or Terraform modules.
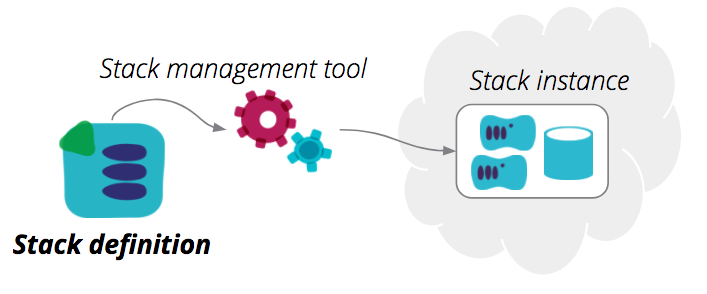
Below is an example stack definition, a Terraform project:
stack-definition/
├── src/
│ ├── backend.tf
│ ├── bastion.tf
│ ├── dns.tf
│ ├── load_balancers.tf
│ ├── networking.tf
│ ├── outputs.tf
│ ├── provider.tf
│ ├── variables.tf
│ └── webserver.tf
└── test/
This stack is part of my standalone service stack template project in github.
Stack instances
A stack definition can be used to provision, and update, one or more stack instances. This is an important point, because many people tend to use a separate stack definition for each of their stack instances - what I called Separate stack definition for each environment in my post on environment pipelines.
But as I explained in that post, this approach gets messy when you grow beyond very simple setups, particularly for teams. I prefer to use a single, parameterized stack definition template, to provision multiple environment instances.
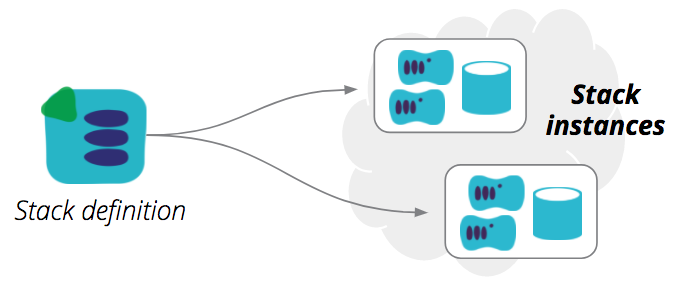
A properly implemented stack definition can be used to create multiple stack instances. This helps to keep multiple environments configured consistently, without having to copy code between projects, with potential for mistakes and mess. Nicki Watt has a great talk on Evolving Your Infrastructure with Terraform which very clearly explains these concepts (and more).
Another benefit of parameterized stacks is that you can very easily create ad-hoc environments. Developers working on infrastructure code locally can spin up their own stack instances by running Terraform with appropriate parameters. Environments can be spun up on demand for testing, demos, showcases, etc., without creating bottlenecks or “freezing” environments. I never want to hear, “nobody touch QA for the next 3 days, we’re getting ready for a big presentation!”
A note on state
One of the pain points of using Terraform is dealing with statefiles. All stack management tools, including CloudFormation, etc., maintain data structures that reflect which infrastructure elements belong to a given stack instance.
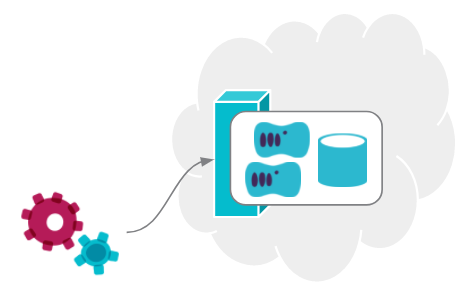
CloudFormation and similar tools provided by cloud platform vendors have the advantage of being able to manage instance state transparently - they keep these data structures on their servers. Terraform and other third party tools need to do this themselves.
Arguably, the explicit state management of Terraform gives you more control and transparency. When your CloudFormation stack gets wedged, you can’t examine the state data structures to see what’s happening. And you (and third parties) have the option of writing tools that use the state data for various purposes. But it does require you to put a bit more work into keeping track of statefiles and making sure they’re available when running the stack management tool.
Example of parameterized infrastructure
I have an example of a parameterized infrastructure stack project on github, using Terraform and AWS. Below is a (trimmed) snippet of code for a webserver.
resource "aws_instance" "webserver" {
...
tags {
Name = "webserver-${var.service}-${var.component}-${var.deployment_id}"
DeploymentIdentifier = "${var.deployment_id}"
Service = "${var.service}"
Component = "${var.component}"
}
}
This shows how it a number of variables are used to set tags, including a Name tag, to distinguish this server instance from other instances of the same server in other stack instances.
These variables are passed to the terraform command by a Makefile:
TERRAFORM_VARS=\
-var "deployment_id=$(DEPLOYMENT_ID)" \
-var "component=$(COMPONENT)" \
-var "service=$(SERVICE)"
up: init ## Create or update the stack
terraform apply $(TERRAFORM_VARS) -auto-approve
The SERVICE and COMPONENT variables are set by a file in the stack definition project, and are always the same. The DEPLOYMENT_ID variable is passed to the Makefile when make is run. The pipeline stage configuration sets this, so for example, the production stage configuration (using AWS CodeBuild in this case) includes the following:
resource "aws_codebuild_project" "prodapply-project" {
name = "${var.service}-${var.component}-${var.estate_id}-ApplyToProdEnvironment"
...
environment {
environment_variable {
"name" = "DEPLOYMENT_ID"
"value" = "prod"
}
}
The codebuild project simply runs make up, and our stack definition creates our webserver instance accordingly.
There’s more
The examples I’ve given imply each environment is a single stack. In practice, as environments grow, it’s useful to split them into multiple, independently managed stacks. I’ll elaborate on this in future posts.

