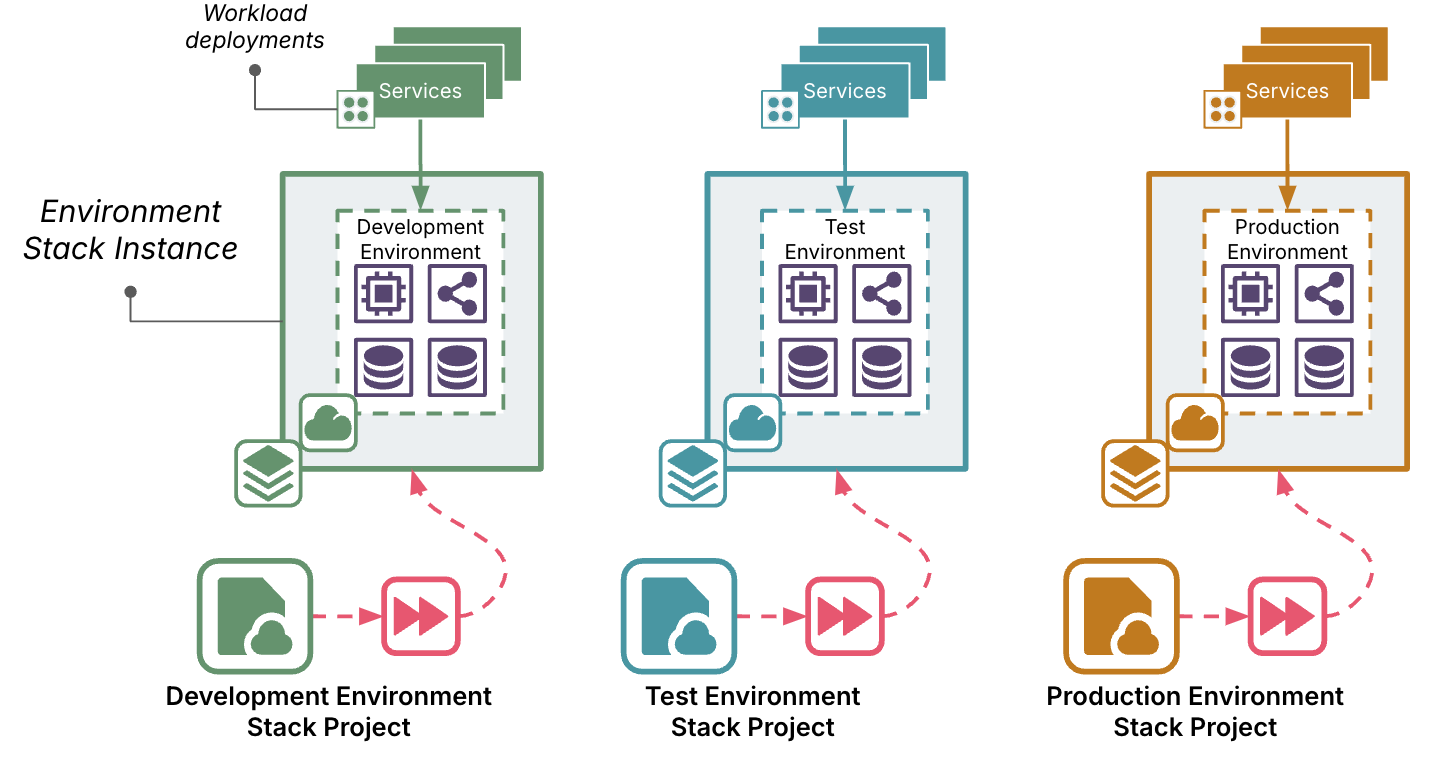
Github introduced the pull request practice, and features to support it, to make it easier for people who run open-source projects to accept contributions from outside their group of trusted committers.
Committers are trusted to make changes to the codebase routinely. But a change from a random outsider needs to be assessed to make sure it works, doesn’t take the project in an unwanted direction, and meets the standards for style and quality. The outsider packages their proposed change as a pull request, which a committer can easily review and manage as a unit before merging it into the codebase.
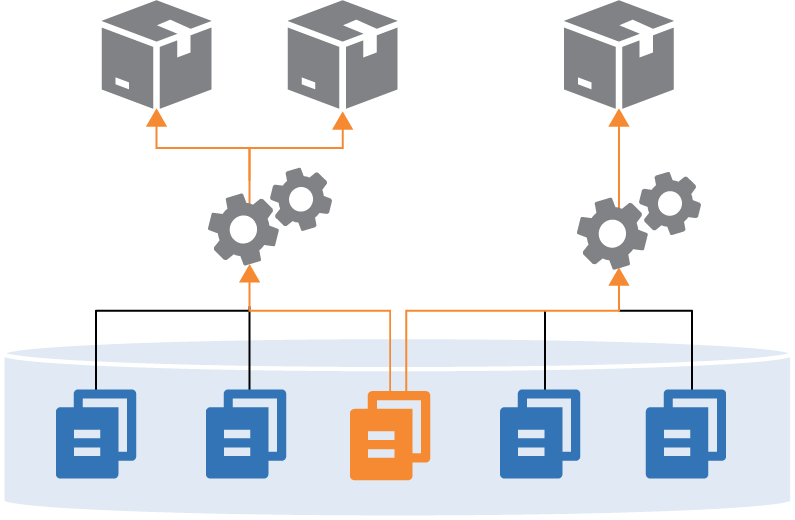
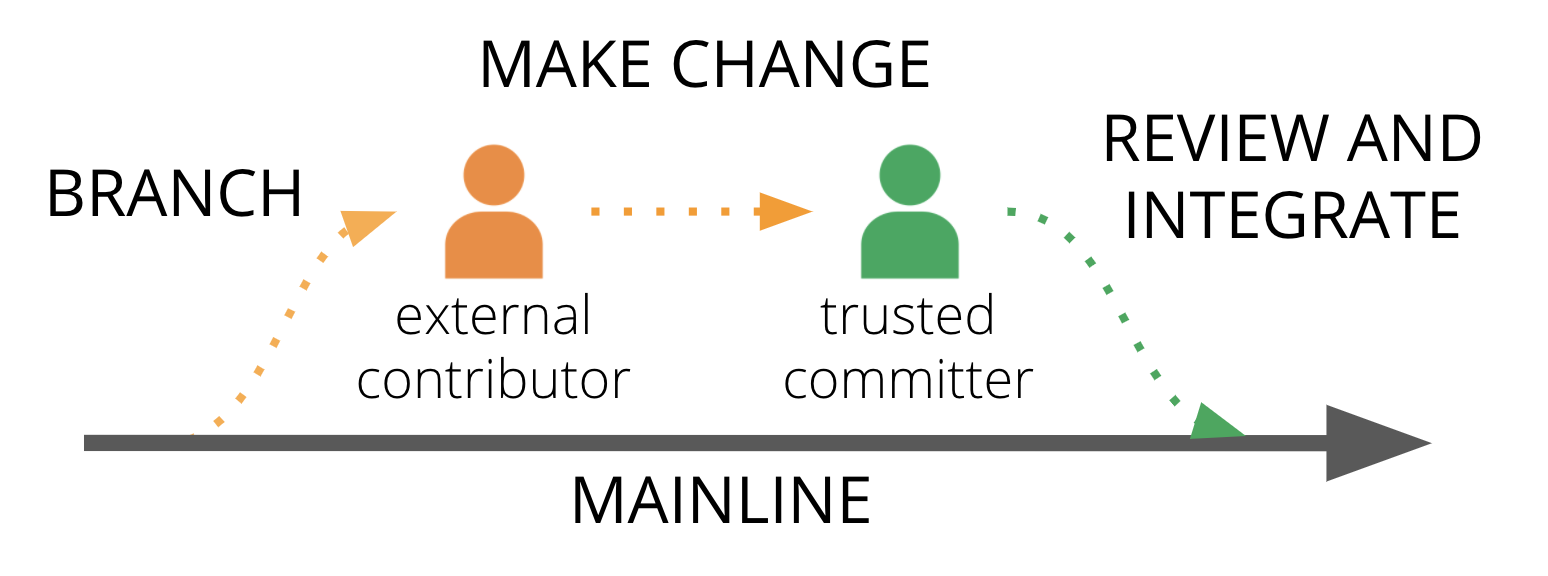 Figure 1: Pull request process
Figure 1: Pull request process
Although designed to make it easier to accept contributions from untrusted people outside a team, many teams now use pull requests for people inside their own team. This practice has become so common that many people consider it a default, “best” practice. Some people assume there is no other way to make sure code is reviewed because they’ve never seen anything else.
However, pull requests sacrifice performance, including both delivery time and quality. This is a sacrifice worth making to manage the risk of accepting changes from unknown people. An outsider may not understand the vision and direction of your project. They may not have the same habits and norms for testing, code quality, and style. However, your own team members should share these norms.
Using pull requests for code changes by your own team members is like having your family members go through an airport security checkpoint to enter your home. It’s a costly solution to a different problem.
Using Continuous Integration rather than pull requests
A software delivery process should optimize for flow and quality. Keep the lead time for changes low, and give fast feedback when a change introduces a problem. This is the idea that underpins Continuous Integration (CI). CI is the practice of continuously merging and testing everyone’s code as they work on it.
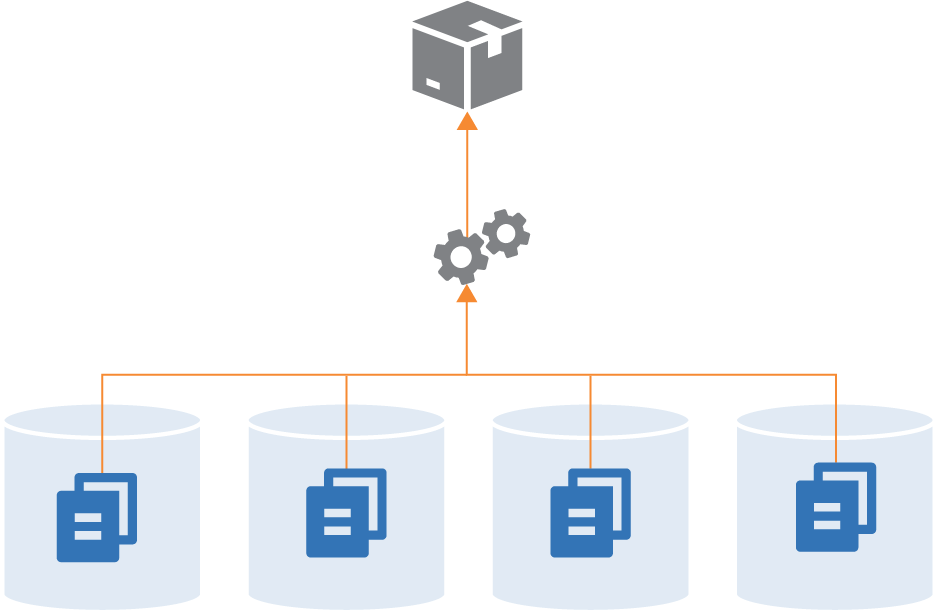
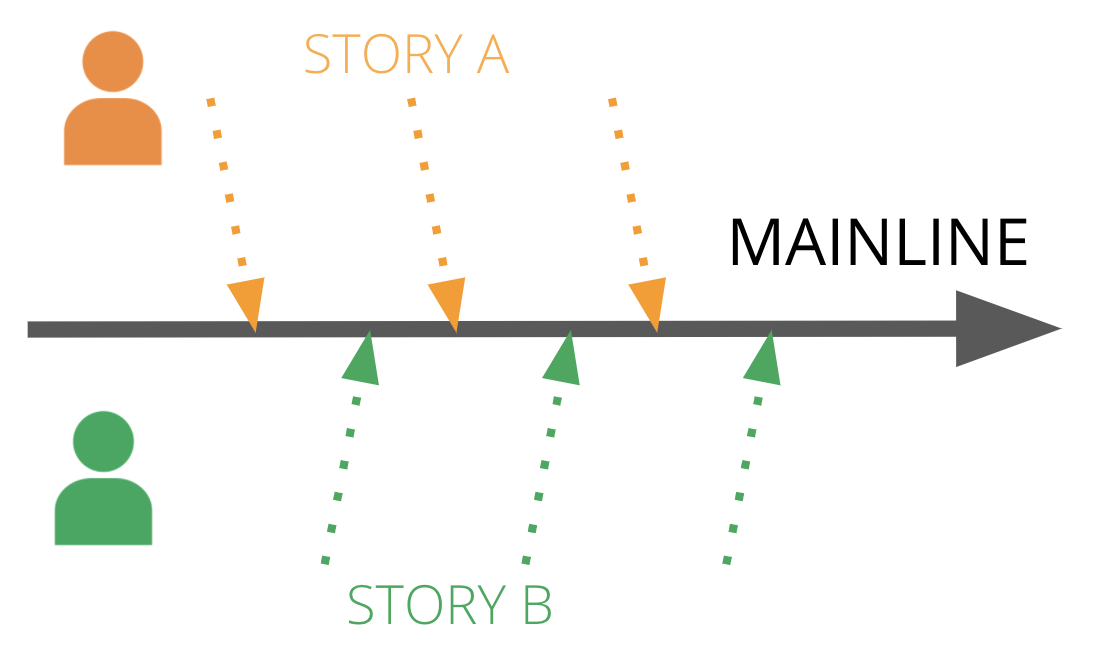 Figure 2: Continuous Integration process
Figure 2: Continuous Integration process
“As they work on it” is essential. As a team member, you don’t wait until you have finished a feature or story to integrate your code to the mainline. Instead, you frequently - at least once a day - put your code into a healthy state that passes tests and integrate it into the mainline with everyone else’s current work. (Also see Martin Fowler’s article on branching patterns and Paul Hammant’s trunk-based development site.)
A CI build job automatically tests the project’s mainline every time you push a change. This means you find out immediately if what you’re doing clashes with something another person is working on before either of you has invested too much time. It sucks to think you’ve finished a story or feature, only to discover you’ve got to go back and untangle and redo several days of effort.
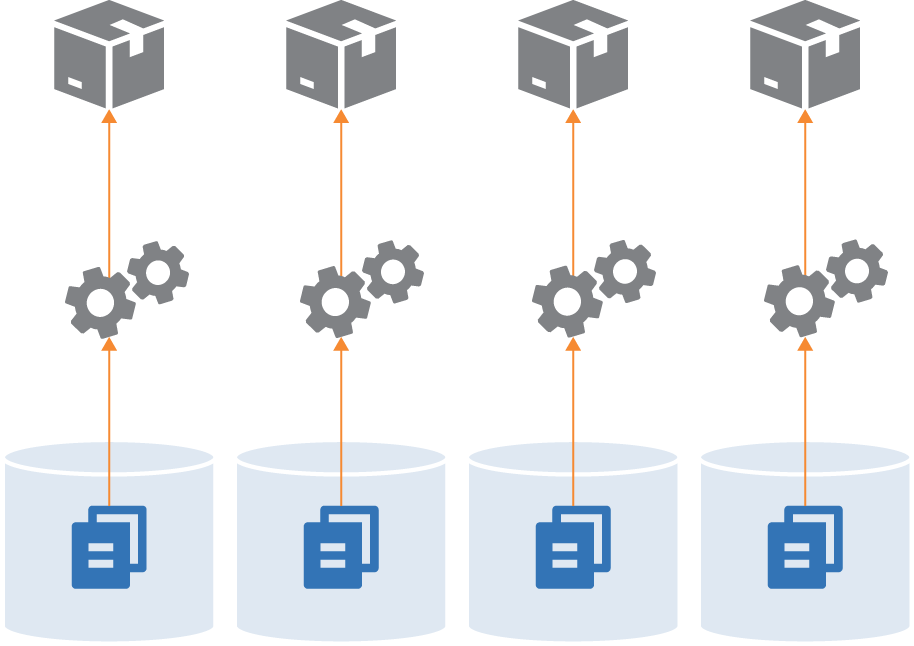
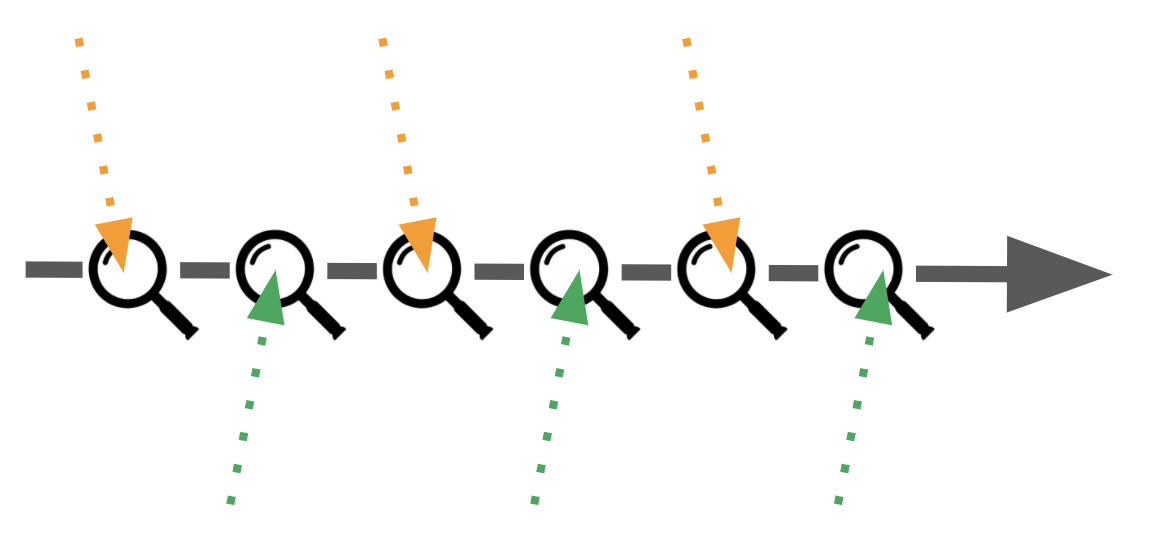 Figure 3: Tests run on integrated code on every push
Figure 3: Tests run on integrated code on every push
The trouble with pull requests
A pull request introduces a delay to integration. When you complete work that you consider ready to integrate with the rest of the team, you create a pull request and wait for someone to review it. Only after someone else reviews the change do they integrate it with the mainline.
If team members are quick to review and integrate pull requests, this is only slightly slower than CI. Maybe they respond and review your change within 30 minutes every time you push. Your code change is integrated with the mainline and automated tests run against it. So you may discover a clash with someone else’s work after 30-40 minutes or so.
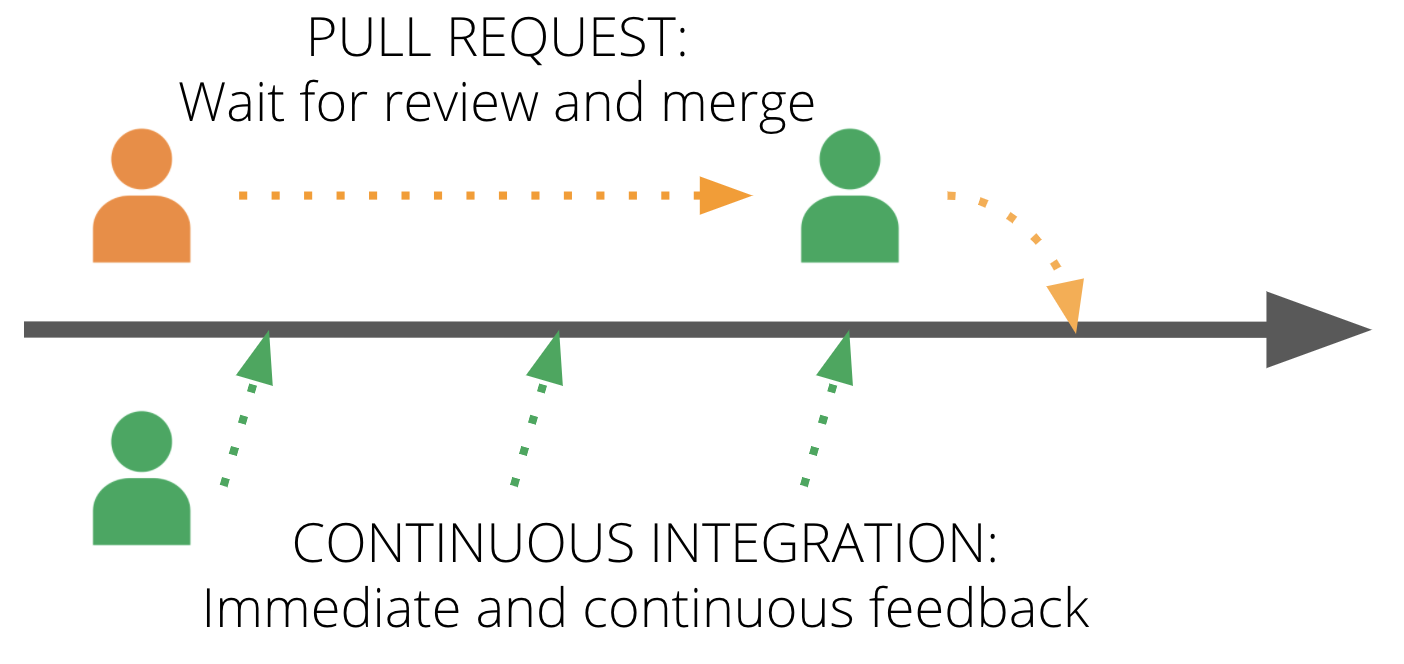 Figure 4: Delays in feedback with pull requests versus CI
Figure 4: Delays in feedback with pull requests versus CI
In practice, not many teams reliably turn pull requests around in under 30 minutes. While waiting for someone to review your change, you may switch to another task or start working on a new change. When you find out there was a problem, you need to switch gears back to the original change, disrupting your flow of work.
An effective CI build, on the other hand, should finish testing your integrated code within a few minutes after you push it - up to 10 minutes in our scenario. You discover that clash almost immediately, so you can investigate and fix it while it’s fresh in your mind.
You don’t need to interrupt someone else’s work to ask them to review it before you get the feedback from testing fully integrated code. As I’ll explain shortly, you may still have someone review your changes. But you can take advantage of a faster cycle time to commit, integrate, and test your code to make multiple changes before asking them to review.
Even if everyone in the team turns pull requests around quickly, the typical practice is to wait until completing work on a feature or story before integrating a pull request with the mainline. Most teams take longer than a day, on average, to develop a story. So a typical pull request process doesn’t meet the minimum requirement of Continuous Integration to integrate everyone’s work at least daily.
Working in a rhythm of coding, pulling, testing, pushing, and getting feedback from integrated tests several times a day is electrifying. And it isn’t possible with pull requests that introduce a human delay into the rhythm.
Better ways to review code changes
When the topic of CI versus pull requests comes up, someone inevitably defends pull requests as necessary to get feedback from other team members on changes.
It is essential to have a second pair of eyes (if not more) looking at code changes. Humans catch problems that tests don’t, especially problems related to maintainability and sound design. Having people review each others’ code also helps the team converge on norms for coding style, programming idioms, and quality expectations. And in some cases, such as regulated environments, having each change reviewed by a second person is required.
However, the recent popularity of pull requests seems to have resulted in some people assuming there are no other ways to review code changes. Here are a few practices that you can use instead, without interrupting the Continuous Integration feedback cycle. Keep in mind that it’s entirely possible to combine more than one of these as appropriate.
 Figure 5: Pairing for immediate, continuous code review
Figure 5: Pairing for immediate, continuous code review
Pair programming: No form of code review is more effective than pairing. Feedback is immediate, so there is a far higher chance you will use it to make improvements. If someone tells you as you write some code that there’s a better way, you can stop, learn, and write it in that better way, right then. If someone tells you a day later, you might take it on board for future reference. But it needs to be a serious problem to get you to stop your current work to go back and redo something you’ve already finished.
Periodic reviews: If a review is not explicitly required for compliance, it may not need to be a gate for each code change. You might have regular, scheduled reviews, for example weekly, where people check through code changes since the last review. This can be especially potent as a group exercise since it creates conversations that help people learn and shape the team’s norms for coding.
Pipeline approvals: If your team uses a Continuous Delivery pipeline to deliver changes to production, you can include a stage that requires someone to authorize the change to progress. This is conceptually similar to a pull request in that it is a gate in the delivery process, but you place the gate after code integration and automated tests. Doing this means that a human only spends time reviewing code that has already been proven technically correct.
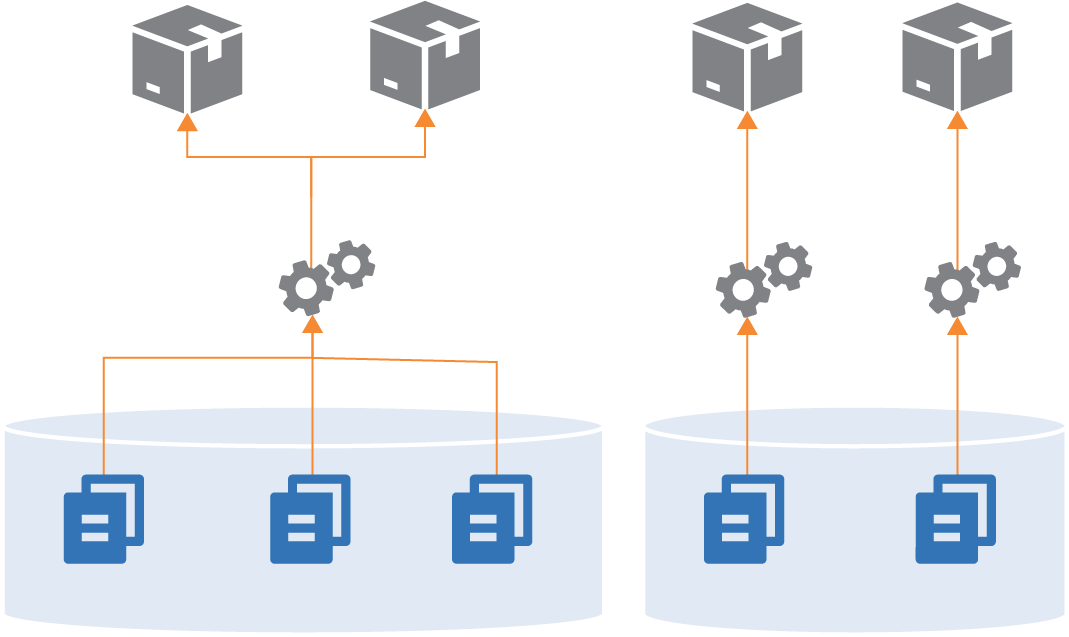
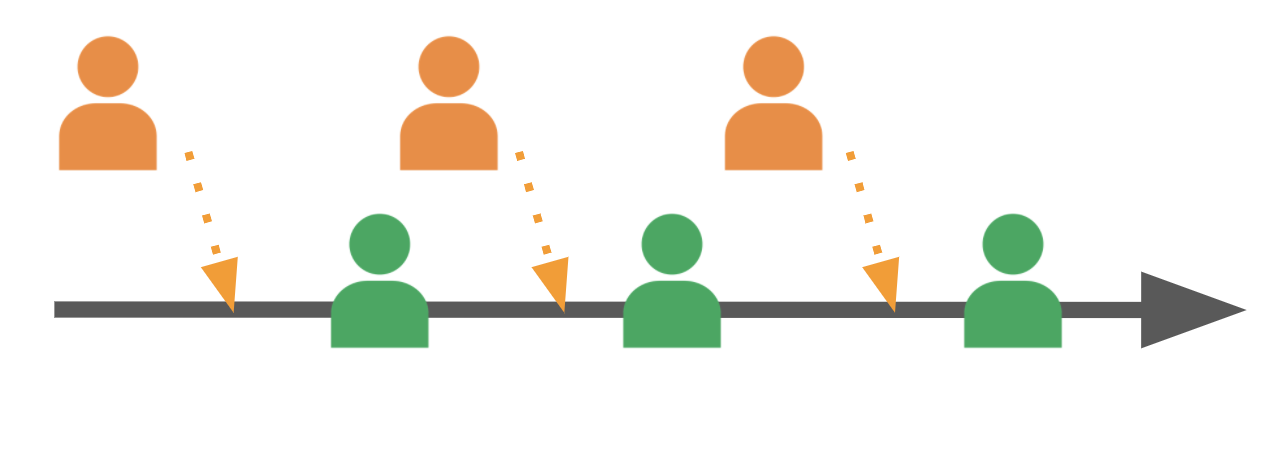 Figure 6: Review changes after they are integrated and tested
Figure 6: Review changes after they are integrated and tested
Conclusion
Pull requests differ from Continuous Integration in having a human review a code change after writing it but before integrating it with the mainline. This creates a delay in getting feedback from automated tests against fully integrated code.
With Continuous Integration, code is either reviewed as it is written (pairing), or after it is integrated and tested. Optimizing the loop for integrating and testing changes means you can run this loop more frequently. A more frequent coding and integration loop encourages developers to make smaller and more frequent commits, which improves quality and flow.
]]>