(Part 2 of The Infrastructure Automation Problem)
In my previous article, I observed that many engineering leaders find infrastructure management to be a bottleneck for software delivery, even after adopting cloud and infrastructure automation. Development teams are blocked waiting for environments to be built, updated, modified, extended, and fixed. There never seem to be enough environments, and yet cloud costs spiral. Messy and fragile environments are a bottleneck for developing and releasing changes. Infrastructure and platform teams are overstretched while technical debt piles up.
That article described some of the approaches tool vendors are taking to make it easier to work with infrastructure, moving past the limitations of the traditional Infrastructure as Code model. Using general purpose programming languages, embedding infrastructure code within application code, using dynamic models of infrastructure rather than static code, and using Generative AI all have the potential to make infrastructure more accessible to its users.
But as powerful as some of these approaches are, I believe that, in themselves, they don’t address the root issues that stop organizations from getting as much value as they should from cloud infrastructure. Why not? Because they focus on improving the efficiency of specific infrastructure management tasks rather than improving the end-to-end value streams that rely on infrastructure.
The value that infrastructure provides to an organization is not in the specific tasks of provisioning or updating infrastructure. It’s in the outcomes that are achieved by the direct and indirect users of the infrastructure.
In this article I describe an approach for identifying what value organizations get from digital infrastructure and how to trace that to the specific infrastructure delivery capabilities. I discuss how analyzing value streams that depend on infrastructure capabilities, particularly software delivery value streams, can identify opportunities to remove bottlenecks. Then I touch on how different approaches for delivering infrastructure capabilities can help with those bottlenecks, such as self-service delivery.
This article lays the foundation for some follow-up content I’m planning that discusses how to implement infrastructure delivery capabilities that improve the end-to-end effectiveness of value streams that rely on infrastructure. The good news is, many of the tool vendors who are working on ways to improve the experience of working directly with infrastructure are also working on ways to improve delivery and outcomes. My goal with this series is to help with thinking about how to design, select, and implement solutions using a value-driven approach.
Does infrastructure have business value?
It’s worth repeating, the value of infrastructure management isn’t measured by how quickly infrastructure resources are deployed and changed; it’s measured by the outcomes delivered by those who use those resources. Digital infrastructure usually has multiple layers of stakeholders represented in a value chain with the organization’s customers at the end.
At that end of the value chain, where revenue is earned, the contribution of infrastructure is indirect and usually unclear. At the opposite end it can be hard to see exactly what value we get from each network route we configure and storage bucket we provision.
Unfortunately, infrastructure is most clearly visible to the business as cost and failure.
This gap makes it tempting to dismiss decisions about infrastructure work as irrelevant to business value. It’s common for business leaders to assume that infrastructure is an undifferentiated utility akin to plumbing. Even many infrastructure engineers don’t see the need to understand the workloads that run on their systems, much less their organization’s strategy.
But if infrastructure didn’t need to be tailored to the organization then we wouldn’t have a constant stream of new buzzwords and movements popping up focusing on doing just that. DevOps, SRE, platform engineering, developer experience - these all continue to get attention because there is a layer of capabilities that needs to be built on top of the low-level IaaS cloud in order for software teams to deliver value specific to their organization.
The hyperscale cloud vendors have done a pretty good job of finding the line where infrastructure really is a utility and putting it behind IaaS APIs. Assembling the undifferentiated resources the APIs provide into useful services for your team to use turns out to need custom work, and plenty of it. Hordes of vendors of all sizes promise turnkey solutions to make that work disappear, and yet it still hasn’t disappeared.
So if cloud and platform vendors can’t give us a generic, one-size-fits-all solution for making the cloud directly useful to our organization, then we need to roll up our sleeves. Our first step is to work out what our organization, specifically, needs from our infrastructure.
What value does infrastructure deliver for your organization?
A good place to start understanding how to get the most value from infrastructure automation is to look at the organization’s strategy, goals, and plans, and think about where infrastructure plays a role. Here are a few examples I’ve come across multiple times with clients:
The business grows and sustains revenue by delivering new digital products and services, and delivering new features, improvements, and fixes to existing products. Infrastructure plays a key role in making sure that software delivery teams have what they need to develop and deliver code into production quickly, reliably, and safely.
The company expands into markets by deploying existing products to new geographical regions and new customers. These different types of expansion often involve building and maintaining new production infrastructure.
The organization manages costs and improves operational effectiveness by consolidating digital services created by different teams, including acquired businesses. This is often a pure infrastructure play, such as working out how to reduce eight different Kubernetes implementations to a more reasonable number.
These activities can usually be mapped to revenues and costs, which makes it possible to attribute financial value to high-level infrastructure delivery capabilities. We can work out those high-level capabilities by looking at the value chain for a given business activity, analyzing the value streams that support that value chain, and then understanding which infrastructure delivery capabilities are most important for improving those value streams.
For example, an online travel business has a goal to increase revenues, which they can achieve by increasing the number of bookings. Product and UX research suggests bookings could be increased by adding a new AI feature for users searching for flights. The development team will implement the new feature in code, and by integrating with an external AI service.
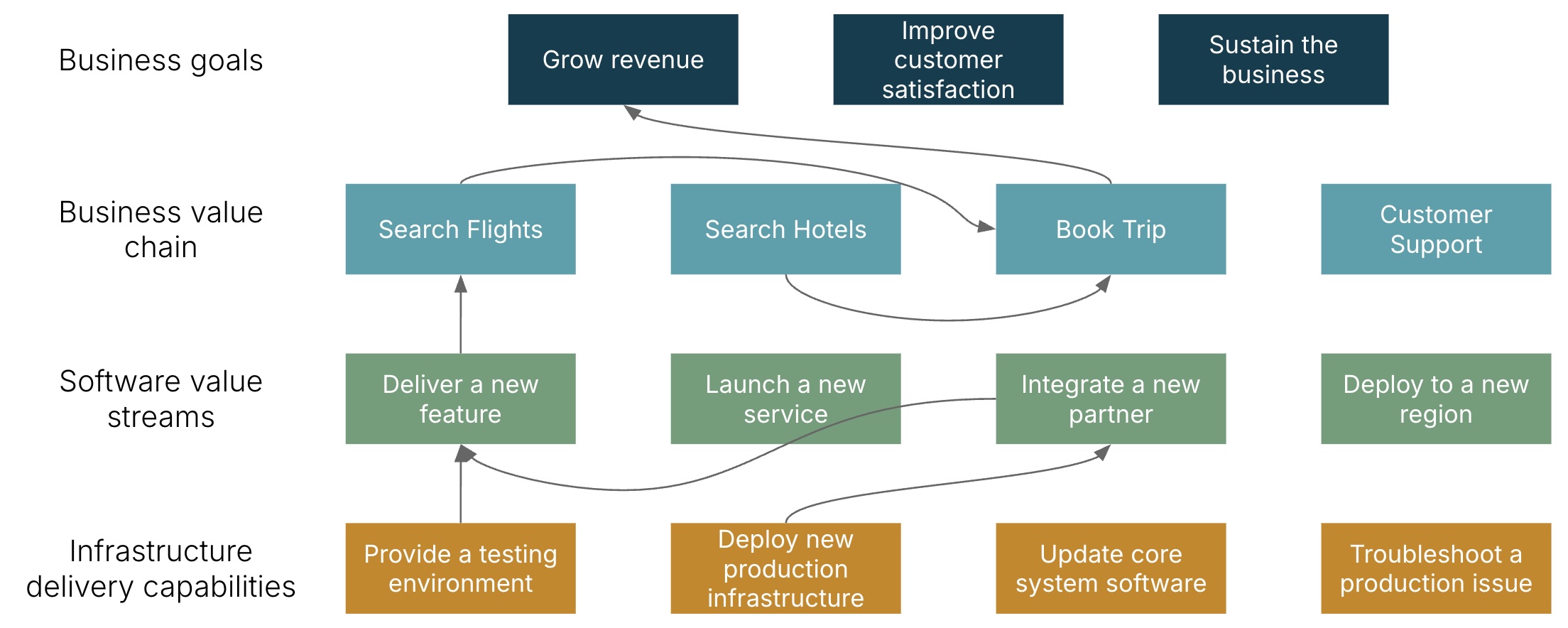
Delivering the new AI flight search feature depends on several infrastructure delivery capabilities, including providing test environments, adding a vector database to all of the environments including production, and changing network configurations to connect with the AI service.
This example shows how to trace the connection between providing an infrastructure delivery capability, like providing an environment to deploy and test a software build, to business goals. The impact of a given infrastructure capability can be assessed by understanding how it contributes to the effectiveness of the value streams it supports. So our next step is to examine one of those value streams.
Measuring software delivery effectiveness
A software delivery value stream traces the process for getting a change into production. The process of developing a new feature, like the travel company’s AI flight search, usually involves delivering a stream of changes into production over the course of weeks or even months. Early changes may be turned off in production, available only to testers and early adopters as development progresses. Once the feature is made available to end users, further changes iterate and evolve the feature based on how it performs commercially and user feedback.
Different types of software changes may be delivered using different value streams (or perhaps different branches of a complex stream). For the purposes of understanding infrastructure effectiveness, there are a number of types of streams that involve infrastructure in different ways. Some examples:
- A software team develops and delivers a code change to production without requiring any changes to existing infrastructure
- A software team develops and delivers a code change to production that requires a change to existing infrastructure
- A product team creates a new software product or service
- A business team introduces existing services to a new customer, requiring adding at least some dedicated-tenancy production infrastructure
The effectiveness of a software delivery value stream can be measured using frameworks like the DORA metrics and the DX platform. The key metrics, per DORA, are time to deliver a change, rate of delivery, production failure rates, and recovery time from production failures.
Once you have an idea of how effective your software delivery value streams are, value stream mapping exercises help to discover ways to improve it. These exercises involve gathering data from various systems and stakeholders to understand the steps involved in delivering a software change. Some key data points to look at within a value stream include:
Cycle times across different stages and subsets of the overall value stream. Where is the most time spent?
Waiting times between steps in the value stream. This leads to investigating the causes of waiting time, which can be a large proportion of cycle times and the overall lead time, and are often related to infrastructure.
Handovers between teams across stages, another common bottleneck. A common handover is when a separate person or team handles a task such as preparing a test environment.
Failure demand, where the value stream loops and extra steps are needed to investigate and correct problems.
Capacity, where there are limits to how many changes can be in progress at a time. These constraints may be because of expertise needed, or system limitations like sharing a test environment across teams.
Effort and expertise needed to execute a step in the value stream. Limits on these can affect capacity and waiting time for handovers. Constraints on expert effort are made worse by failure demand, which soaks up expert time to investigate and fix.
It’s worth noting that, in addition to software delivery, infrastructure can play a role in other value streams including production support and troubleshooting. Additional value streams can be mapped for activities for ensuring operational quality and managing risk, such as patching and upgrading services. Those infrastructure value streams can in turn impact software delivery value streams, for example by taking environments offline for maintenance.
The results of value stream mapping are useful for identifying where to focus efforts to improve the results of the end-to-end delivery process. It’s too common to automate an obvious part of the process that doesn’t make much difference to the big picture. For example, I’ve seen teams proud of having replaced a four-hour manual provisioning process with automation that takes ten minutes, only to discover that the two-week delivery cycle (including design, review, and approval stages) meant their users didn’t notice.
On the other hand, it’s important to understand that the impact of automating a step in the value stream isn’t only about completing that task more quickly. It could have added benefits like removing handovers and cutting waiting times.
Analyzing infrastructure capabilities
Platform and infrastructure improvement initiatives can improve value streams by optimizing underpinning infrastructure capabilities. Some of the software delivery value streams listed earlier involve making changes to infrastructure, like adding a new vector database or opening network connections to an external service’s API. But even with a basic value stream for delivering a software code change that doesn’t need any changes to infrastructure, infrastructure capabilities are required to get the change from the developer’s workspace to production.
For example, releasing a software change normally involves deploying a build with the change to one or more testing environments. The capability of “providing an environment for testing” can impact the effectiveness of the software delivery value stream in various ways, including:
Wait time for an environment to be available. This happens when there are a limited number of environments for a particular type of testing.
Wait time for an environment to be prepared. Configuration and data may need to be reset to a clean starting state after an environment was used for testing another build, especially if the previous build failed.
A failure when deploying or running tests due to an issue with the environment’s configuration or data. This leads to time spent resolving the issue and re-running steps in the value stream. Often resolving failures means asking people from other teams for help.
Issues with wait time and failure can impact the effectiveness of the end-to-end value stream, leading to longer lead times and fewer releases. If problems with providing or preparing environments occur when deploying the software change to production, then deployment failure rate and recovery time metrics will suffer.
There are a number of metrics that can be useful for measuring the capability of providing an environment for testing:
- How long does it take before the environment is ready to use? What is the turnaround time between deployments? What is the wait time for deployment?
- What are the capacity limits - how many of a given type of environment can be made available at a time? What is the demand?
- How much effort does it take to prepare an environment for deployment, and clean up afterwards? What skills are required? For example, it could need an infrastructure engineer, a DBA, and a QA to prepare an environment and its data.
- What is the frequency of failures in an environment, whether it’s a deployment failure or a test failure caused by an issue with the infrastructure or data?
- What is the utilization of infrastructure used for testing? Environments that are often idle between occasional deployments rack up wasted cloud spend. Even in a data center it’s a waste to have too much unused hardware capacity.
Improving an infrastructure capability’s effectiveness
An infrastructure capability can be implemented and delivered in different ways, each with varying impacts on the end to end value stream. Once you’ve pinpointed how a capability is creating bottlenecks, you should consider changing the way the capability is provided.
How is the capability implemented?
Static environments with manual preparation represent the least effective option, although the most common. A centralized infrastructure team manually configures and resets environments when needed. This approach introduces handovers between teams, which create waiting times before the deployment step can begin, and limits capacity to the number of pre-built environments. As we saw in the value stream analysis, these bottlenecks can dramatically impact end-to-end delivery effectiveness.
Static environments with automated preparation improves on this by removing some manual effort and reducing preparation time. Define the starting state, including data, dependencies, integration points, configuration settings, etc., and have a way to automatically reset the environment to that state. This reduces waiting times for environment preparation and can eliminate some handovers. However, teams may still wait for an environment to be available. The mitigation to make sure there is enough capacity to prevent teams from waiting is to keep enough environments provisioned to meet peak demand, which can lead to low utilization (i.e. wasted hardware or cloud spend). Also, automated environment preparation needs to be highly reliable. Failures not only lead to delays, but also the need to ask someone else to help, adding to the effort absorbed. Destroying and rebuilding the environment each time tends to be a more reliable approach than cleaning up a running environment, but also slower.
Ephemeral environments - build and destroy on demand - is the most effective approach. This builds on automated preparation but goes further by creating environments only when needed and destroying them when done. You get better utilization and cost management if you destroy or strip down environments when they aren’t in use. If you have the ability to add capacity on demand, whether by using cloud or a shared pool of data center resources, you can eliminate waiting times for environment availability. This approach can dramatically reduce cycle times and remove capacity constraints from the value stream.
Service delivery models
Beyond the technical implementation, the effectiveness of an infrastructure capability also depends on who provides it and how. Typical approaches are:
Centralized specialist teams handle all requests for the capability. This creates handovers and waiting times in the value stream, as software teams must request environments and wait for them to be provided.
Embedded specialists within software delivery teams (such as DevOps engineers) can reduce handovers and waiting times, though they may become bottlenecks themselves when multiple developers in a team need help. DevOps skills are also in high demand, so it’s often not feasible to hire people in every team for this.
Self-service capabilities that allow anyone authorized in the software team to provision what they need (for example, using a developer portal) can eliminate handovers entirely and remove waiting times from the value stream.
Fully automated provision, for example, integrated into deployment pipelines, represents the ultimate evolution, where environments are created and destroyed as part of the automated software delivery process without human intervention.
Each progression toward greater automation and self-service reduces the bottlenecks, handovers, and waiting times that impact software delivery value stream effectiveness.
Implementing better infrastructure delivery
The value of infrastructure management is in the outcomes of the work done by the people and teams who use the infrastructure. I recommend that engineering leaders who want to make infrastructure delivery more useful to the organization start by tracing the connections from business goals and value chains down to infrastructure management capabilities. This article has outlined an approach to do this to identify ways to use infrastructure automation to improve business outcomes.
I’ve used software delivery to illustrate this approach because it’s one of the easier parts of the value chain to trace the connection from business goals to infrastructure delivery.. Software is developed with specific business outcomes in mind, so it should be easy to understand the value in automating the process of providing test environments to make the end-to-end software delivery process faster and more reliable.
With other infrastructure capabilities, like ensuring systems are continuously patched and upgraded, and adding automated backups and failovers, the connections can be less obvious. But it’s entirely possible to make those connections using this approach, and it’s essential for avoiding accumulating invisible but potentially existential risk and inefficiency.
Understanding the value of improving infrastructure delivery is only the first step in making it happen. As I’ve suggested, business outcomes can often be improved by changing the way infrastructure capabilities are implemented. Automating tasks to provision and change infrastructure will only make the end-to-end processes the infrastructure supports better if they’re designed and implemented with an understanding of that process in mind.
I plan to expand on how to do that in later articles in this series. As a preview, there are three key elements of implementing infrastructure delivery to support effective value streams for infrastructure users. One is team structures and workflows. I’ll draw Team Topologies as well as continuing with value stream mapping to describe some different ways of providing infrastructure services. The second element is architecture, which is essentially about implementing infrastructure as composable components at two different levels, one for deployment (stacks) and one for consumption (compositions). My thinking here is heavily influenced by microservices, ports and adapters, and product thinking. The third element is delivery, which is the nuts and bolts of packaging, delivering, deploying, configuring, and integrating infrastructure components.
Although it sounds like I could describe each of these elements in a separate article, I think they’re too tightly connected to explain separately. My next article will probably be a fairly high-level description of these three elements and how they work together. Stay tuned!
Image by Deleece Cook


