One of the early promises of Infrastructure as Code was to do away with snowflake servers. In the old times, we built servers by logging into them and running commands. We might build, update, fix, optimize, or otherwise change servers in different environments in different ways at different times. This led to configuration drift, which was what we called inconsistencies between servers across the path to production. Configuration drift meant that deploying an application to any environment was a laborious process of tweaking and fixing.
Definition drift
It’s significant that these days, “configuration drift” has come to mean inconsistency between code and the infrastructure deployed in an environment. This reflects the mindset that each environment has its own copy of infrastructure code, managed in a separate branch or folder. In theory, the code is identical across these copies, but in practice people tend to make environment-specific changes to code.
- They make a fix in production but don’t bother to make the same change to development and test environments because the problem doesn’t show up there.
- They start working on a new idea in a test environment, but other priorities mean they leave it unfinished.
- They need configuration differences in different environments - resource sizing, for example - but don’t have time to implement it as a parameter, so they hard-code the value separately in each environment.
Maintaining separate, inconsistent copies of infrastructure code for different environment that should be essentially consistent is an antipattern, Snowflakes as Code.
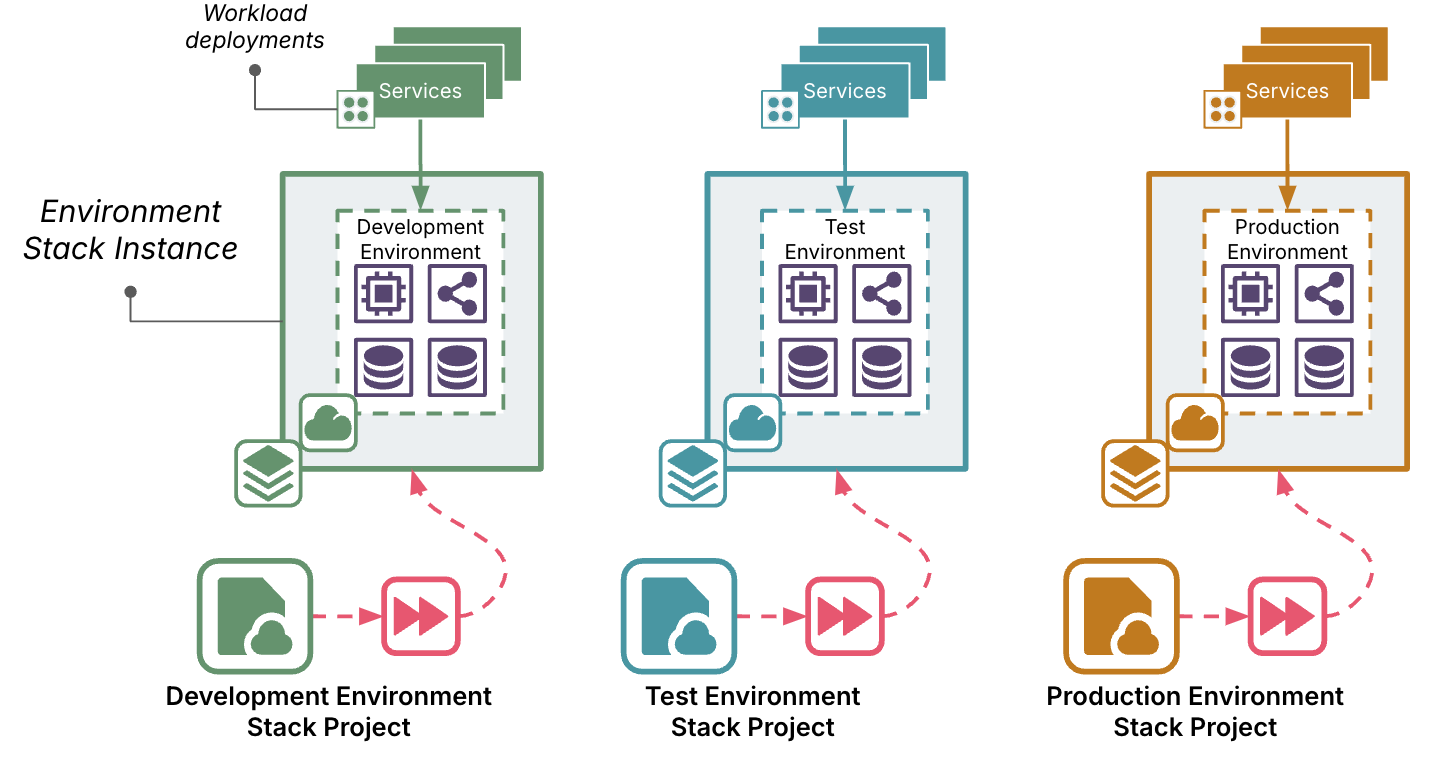
Prefer reusable infrastructure over hand-crafted
An alternative to snowflakes as code is to reuse a single instance of infrastructure code for multiple instances of the infrastructure, and manage necessary variation between environments with parameters. Chapter 7 of the third edition of the Infrastructure as Code book describes building reusable infrastructure stacks, and chapter 8 goes into some different way of managing configuration parameters for those stacks.
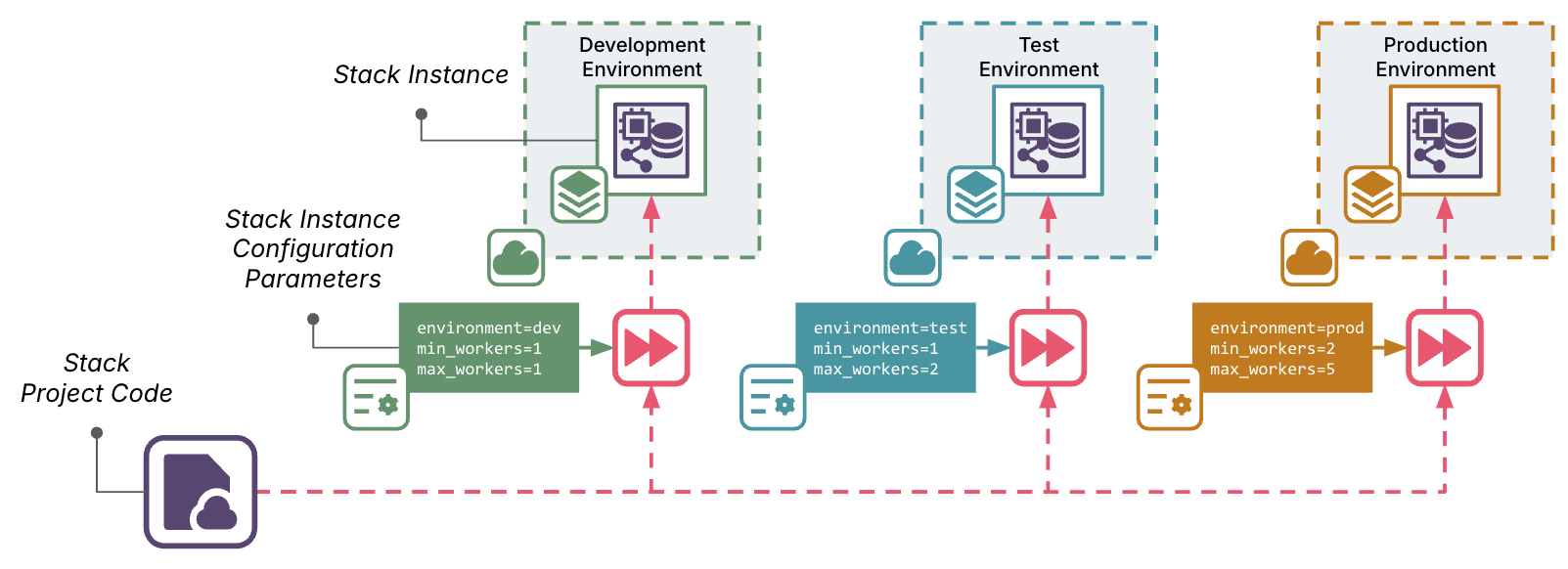
You can maintain multiple versions of the code so that you can apply changes to different instances at different times, for example so you can have a pipeline to deliver changes to environments in a path to production. But code for an existing version should never be edited. This is Continuous Delivery 101 - only make changes in the origin (for example, trunk), then copy the code, unmodified, from one environment to the next. A given build of infrastructure code should be treated as an immutable artifact. See chapters 14 through 17 of the book for infrastructure delivery workflows.
Hand-crafted infrastructure workflows
Many Infrastructure as Code tools today are designed to support workflows where infrastructure engineers hand-craft infrastructure for a single instance, rather than for multiple environments. Infrastructure “pipeline” tools that only support “plan” and “apply” stages for a single environment are one example. Deployment tools based on pull-requests are another example where, often, the assumption is that a given copy of infrastructure code is only deployed to one environment.
There are a growing crop of tools that support infrastructure delivery workflows that involve re-using code rather than maintaining per-environment snowflake tools. I’ve written about some in my post Some interesting infrastructure tools, although I haven’t broken them down based on this criteria. I’m keen to hear about others.
Are environments obsolete?
I’ve had some folks tell me that the entire concept of development and testing environments is obsolete - everything should be deployed into the production environment and tested there, perhaps using dark-launching and other techniques to manage which workloads are exposed to production users. I’ve seen this approach used with newer software systems, where all of the workloads are newly developed from the ground up on homogeneous cloud-native stacks. But as long as large, complex, heterogenous software estates are common there will be a need to provide more strongly separated environments for development and testing of business-critical software.
(Original post 19 November, 2021. Updated 8 January, 2025.)


