Early Release of Infrastructure as Code 3rd edition
I’ve been furiously typing away on the new edition of the book and now have a rough (very!) draft of the first eight chapters. You can get access to the Early Release of Infrastructure as Code 3ed on the O’Reilly Learning Platform (previously known as Safari).
The first eight chapters, of a planning 18 or so, are:
- What Is Infrastructure as Code?
- Principles of Cloud Infrastructure
- Platforms and Toolchains
- Defining Infrastructure as Code
- Design Principles For Infrastructure as Code
- Infrastructure Components
- Design Patterns for Infrastructure Deployment Stacks
- Configuring Stack Deployment Instances
I’ve updated quite a lot over the first two editions. In the earlier chapters I discuss organizational goals, and how to make sure your infratructure strategy and architecture support them.
The chapters on design and component bring in a lot of what I’ve learned over the past four or five years about how to structure infrastructure code for delivery, sharing, and reuse.
While revising the chapter “Defining Infrastructure as Code” I came up with a model for thinking about the different lifecycle contexts of infrastructure code that has proven useful throughout the rest of the book. This chapter is where I talk about the nature of infrastructure coding languages, and led me to think about the different lifecycle contexts of infrastructure code.
These contexts are editing code, deploying code (provisioning infrastructure), and using infrastructure resources, as shown in this diagram:
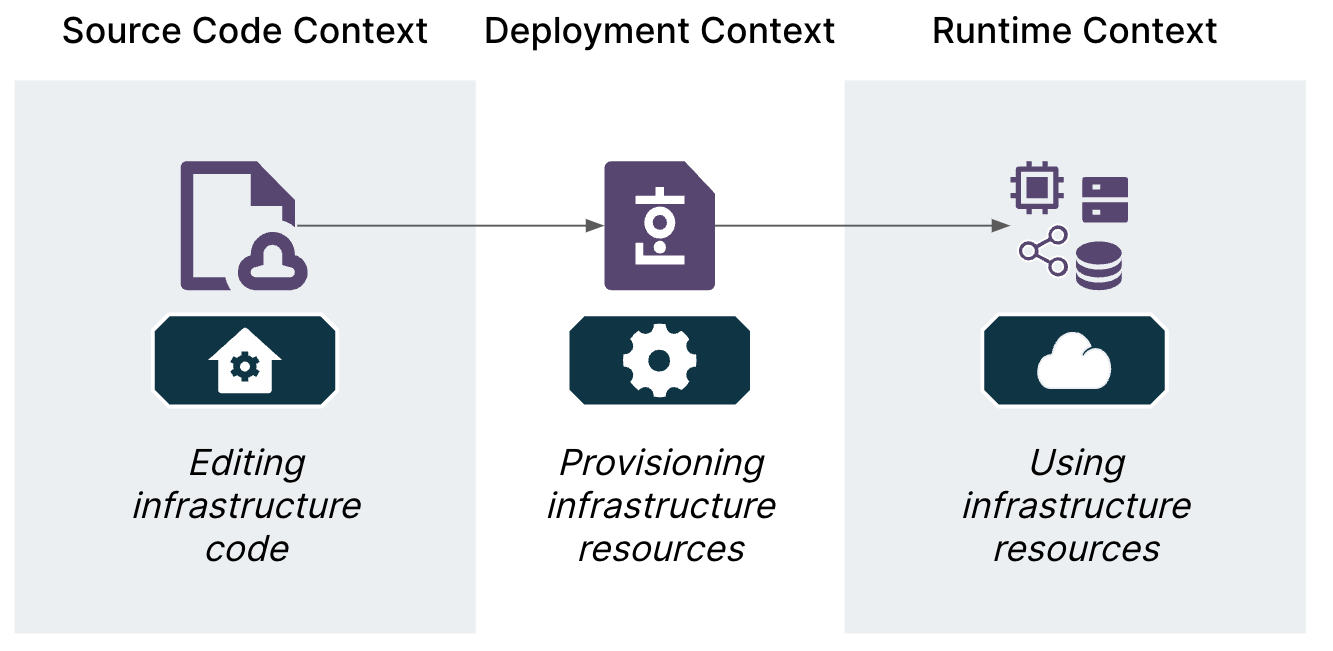
When we talk about infrastructure that we define as code, we often intermix these contexts, leading us to confuse ourselves. We also sometimes forget fundamental differences between application code and infrastructure code.
Application code executes in the runtime context, after having been deployed, while infrastructure code only executes when we deploy it. So, for example, when we write automated tests for procedural code written with Pulumi or CDK, we need to keep in mind exactly what the code is doing. The logic of our code results in a model of infrastructure to be provisioned, but doesn’t tell us how the infrastructure will behave. So we may need separate collections of tests for each context, one set being unit tests, the other testing the infrastructure that is provisioned afterwards.
Another area where this lifecycle context concept is useful is thinking about components. It’s very common to see teams try to deal with very large infrastructure projects by breaking them into code components like Terraform modules. The diagram below uses this to differentiate between a code library and a deployable infrastructure stack.
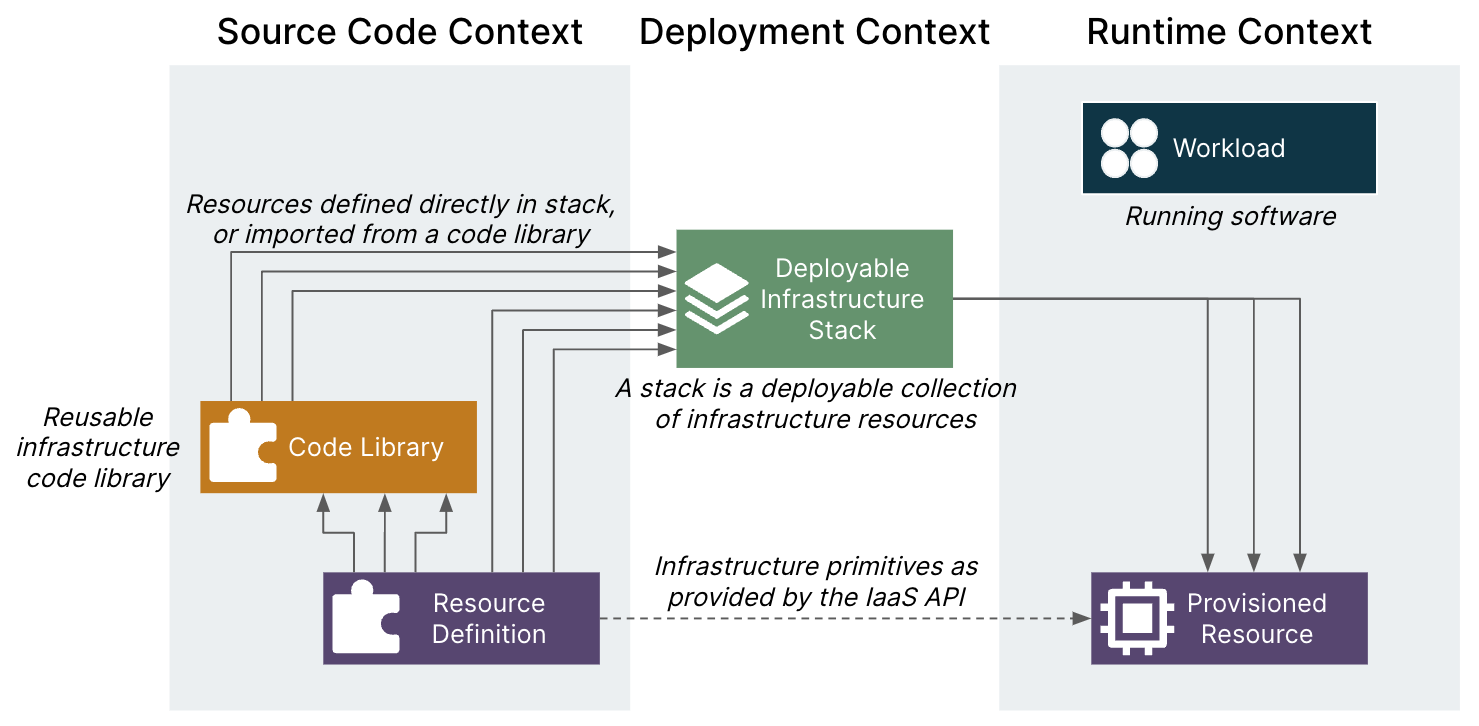
An infrastructure code library, like a Terraform module, Pulumi component resource, or CDK Level 3 construct, is useful to organize and share code. But it is only applied as part of an infrastructure stack like a Terraform project, Pulumi stack, CDK stack, or Crossplane composition.
This is why a major emphasis in my book, going back to the first edition, is designing infrastructure using separately deployable stacks as the main architectural unit.
I’m having fun working on this, and am looking forward to getting it published around the end of the year!


