Using Pipelines to Manage Environments
Tools like Terraform, AWS CloudFormation, Azure Resource Manager Templates, Google Cloud Deployment Manager Templates and OpenStack Heat are a great way to define server infrastructure for deploying software. The configuration to provision, modify, and rebuild an environment is captured in a way that is transparent, repeatable, and testable. Used right, these tools give us confidence to tweak, change, and refactor our infrastructure easily and comfortably.
But as most of us discover after using these tools for a while, there are pitfalls. Any automation tool that makes it easy to roll out a fix across a sprawling infrastructure also makes it easy to roll out a cock-up across a sprawling infrastructure. Have you ever corrupted the /etc/hosts files on every server in your non-production estate, making it impossible to ssh into any of them — or to run the tool again to fix the error? I have.
What we need is a way to make and test changes safely, before applying them to environments that you care about. This is software delivery 101 — always test a new build in a staging environment before deploying it to live. But the best way to structure your infrastructure code to do this isn’t necessarily obvious.
I’m going to describe a few different ways people do this:
- Put all of the environments into a single stack
- Define each environment in a separate stack
- Create a single stack definition and promote it through a pipeline
The nutshell is that the first way is bad; the second way works well for simple setups (two or three environments, not many people working on them), and the third has more moving parts, but works well for larger and more complex groups.
Before diving in, here are a couple of definitions: I use the term stack (or stack instance) to refer to a set of infrastructure that is defined and managed as a unit. This maps directly to an AWS CloudFormation stack, and also to the set of infrastructure corresponding to a Terraform state file. I also talk about a stack definition as a file, or set of files, used by a tool to create a stack. This could be a folder with a bunch of *.tf files for Terraform, or a folder of CloudFormation template files.
I’ll show some code examples using Terraform and AWS, but the concepts apply to pretty much any declarative, “Infrastructure as Code” tool, and any automated, dynamic infrastructure platform.
I’ll also assume two environments — staging and production, for the sake of simplicity. Many teams end up with more environments — development, QA, UAT, performance testing, etc. — but again, the concepts are the same.
One stack with all the environments
This is the most straightforward approach, the one that most people start out using, and the most problematic. All of the environments, from development to production, are defined in a single stack definition, and they are all created and managed as a single stack instance.
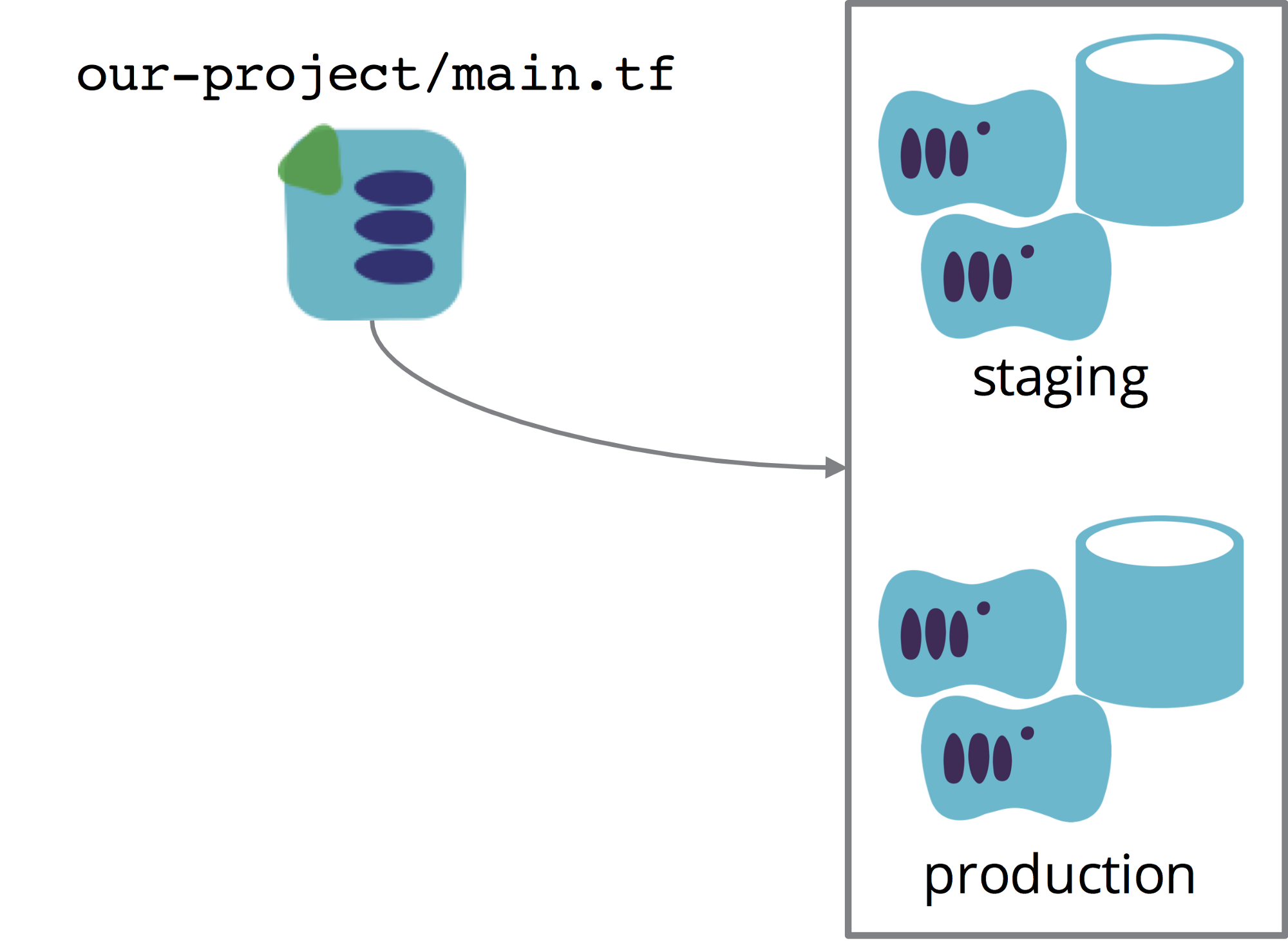
Multiple environments managed as a single stack
The code example below shows a single Terraform configuration for both staging and production environments:
# STAGING ENVIRONMENT
resource "aws_vpc" "staging_vpc" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "staging_subnet" {
vpc_id = "${aws_vpc.staging_vpc.id}"
cidr_block = "10.0.1.0/24"
}
resource "aws_security_group" "staging_access" {
name = "staging_access"
vpc_id = "${aws_vpc.staging_vpc.id}"
}
resource "aws_instance" "staging_server" {
instance_type = "t2.micro"
ami = "ami-ac772edf"
vpc_security_group_ids = ["${aws_security_group.staging_access.id}"]
subnet_id = "${aws_subnet.staging_subnet.id}"
}
# PRODUCTION ENVIRONMENT
resource "aws_vpc" "production_vpc" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "production_subnet" {
vpc_id = "${aws_vpc.production_vpc.id}"
cidr_block = "10.0.1.0/24"
}
resource "aws_security_group" "production_access" {
name = "production_access"
vpc_id = "${aws_vpc.production_vpc.id}"
}
resource "aws_instance" "production_server" {
instance_type = "t2.micro"
ami = "ami-ac772edf"
vpc_security_group_ids = ["${aws_security_group.production_access.id}"]
subnet_id = "${aws_subnet.production_subnet.id}"
}
This is a simple approach that makes everything visible in one place, but it doesn’t isolate the environments from one another. Making a change to the staging environment risks breaking production. And resources may leak or become confused across environments, making it even easier to accidentally affect an environment you don’t mean to.
Charity Majors shared problems she ran into with this approach using Terraform. The blast radius (great term!) of a change is everything included in the stack. And note that this is still true even with tools that don’t use statefiles as Terraform does. Defining multiple environments in a single CloudFormation stack is asking for trouble.
A Separate stack definition for each environment
Charity (and others) suggests splitting your environments into separate stack definitions. Each environment would have its own directory with its own Terraform configuration:
./our-project/staging/main.tf
./our-project/production/main.tf
These two different configurations should be identical, or nearly so. By running your infrastructure tool against each of these separately, you isolate the environments from one another (at least when it comes to using the tool, although obviously they may or may not be isolated in terms of networking, cloud account permissions, etc.) And because each environment has its own set of definition files, the intended state of each environment is very clear.
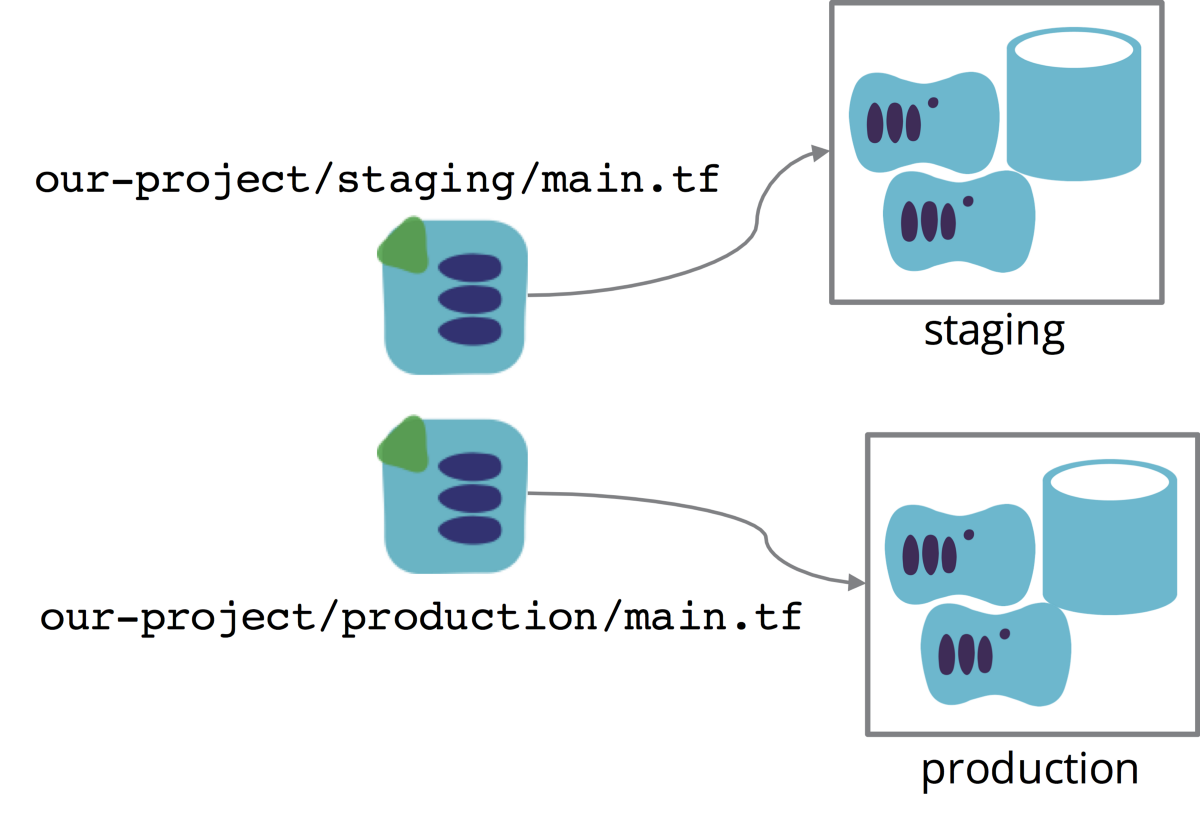
When you need to make a change, you edit the files for the staging environment stack, apply them, and test them. Iterate until it works the way you want. Then make the same changes to the files for the production environment and apply them to the production stack instance.
A drawback with this approach is that it’s easy for differences to creep into environments. Some of these differences may be accidental, as when someone in a rush makes a fix directly to the production environment configuration, and forgets to go back to the other environments to make the same change.
But often, as with statically defined environments, people try things out in different environments, and leave them in when they’re distracted by other tasks. Over time, each environment becomes a snowflake. Even though each environment is defined as code, differences between the environments means there is no trust that a given change can be quickly and safely applied across them all.
So maintaining a separate definition file per environment requires vigilance and discipline to keep them consistent.
Modules can be used to share code across environments, which can help with consistency. But modules can also create tight coupling. Making a change to a shared module requires ensuring the change won’t break other environments. The ability to test a change to a module in one environment before applying it to production adds complexity for versioning and release management.
One stack definition managed with a pipeline
An alternative is to use a continuous delivery pipeline to promote a stack definition file across environments. Each environment has its own stack instance, so the blast radius for a change is contained to the environment.
But a single stack definition is re-used to create and update each environment. The definition can be parameterized, to capture differences between instances, such as cluster sizing. The definition file is versioned, so we have visibility of what code was used for any environment, at any point in time.
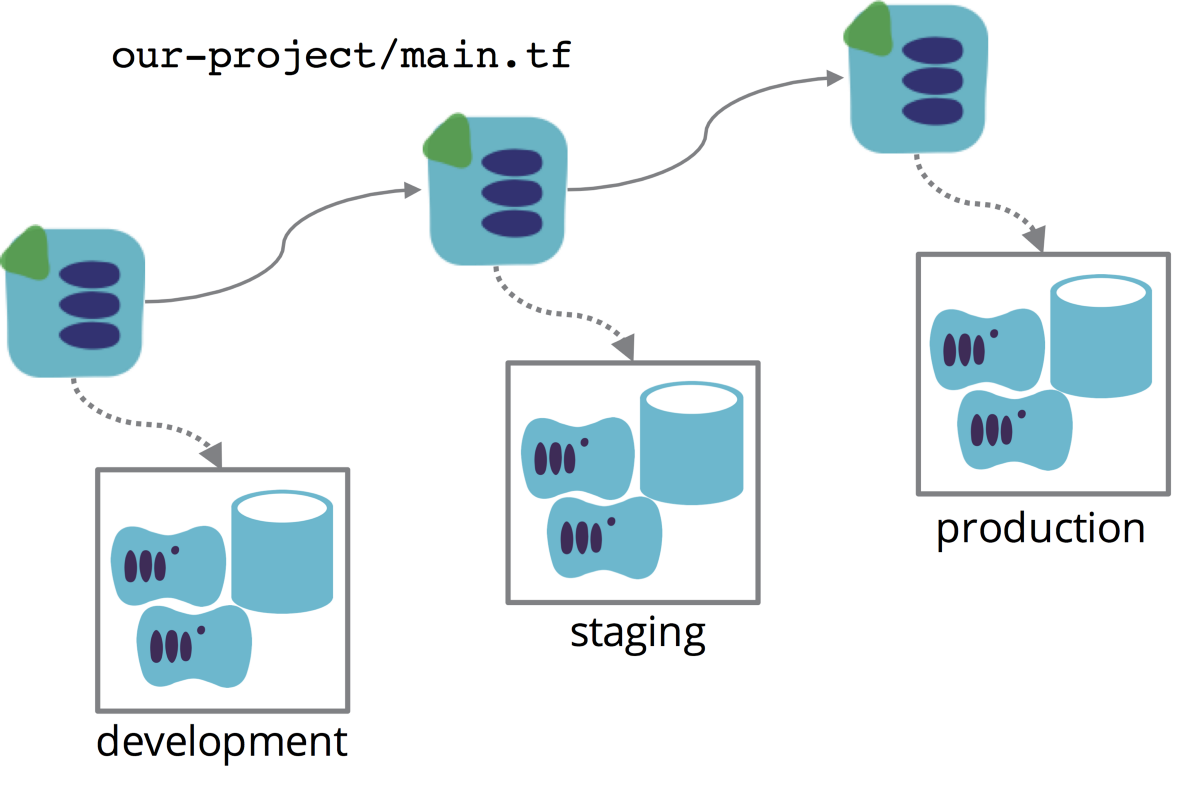
A single definition file used to create multiple stack instances in a pipeline
The moving parts for implementing this are: a source repository, such as a git repository; an artefact repository; and a CI or CD server such as GoCD, Jenkins, etc.
A simple example workflow is:
- Someone commits a change to the source repository.
- The CD server detects the change and puts a copy of the definition files into the artefact repository, with a version number.
- The CD server applies the definition version to the first environment, then runs automated tests to check it.
- Someone triggers the CD server to apply the definition version to production.
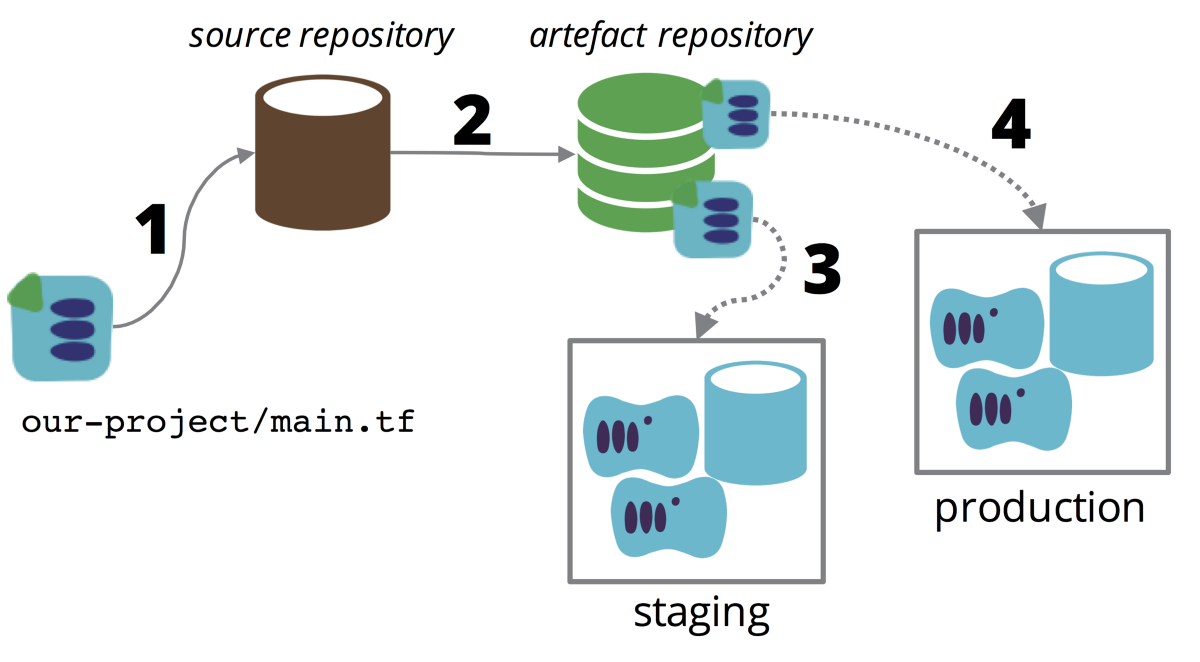 Basic flow of a stack definition through a pipeline
Basic flow of a stack definition through a pipeline
Benefits
Teams I work with use pipelines for infrastructure for the same reasons that development teams use pipelines for their application code. It guarantees that every change has been applied to each environment, and that automated tests have passed. We know that all the environments are defined and created consistently.
With the previous “one stack definition per environment” approach, creating a new environment requires creating a new folder with its own copy of the files. These files then need to be maintained and kept up to date with changes made to other environments.
But the the pipeline approach is more flexible. New environment instances can be spun up on demand, which has a number of benefits:
- Developers can create their own sandbox instances, so they can deploy and test cloud-based applications, or work on changes to the environment definitions, without conflicting with other team members.
- Changes and deployments can be handled using a blue-green approach — create a new instance of the stack, test it, then swap traffic over and destroy the old instance.
- Testers, reviewers, and others can create environments as needed, tearing them down when they’re not being used.
Artefact repository, promotion, and versioning
The pipeline treats a stack definition as a versioned artefact, promoting it from one stage to the next. As per Continuous Delivery, an artefact is never changed. This is why I suggest a separate artefact repository in addition to the version control repository. The version control is used to manage changes to the definition, the artefact repository is used to preserve immutable, versioned artefacts. However, I’ve seen people use their code repository for both, which works fine as long as you ensure that the principle of not making changes to a definition version once it’s been “published” and used for any environment.
For stack definitions, I like to use an S3 bucket (or an equivalent) as a repository. I have a pipeline stage that “publishes” the definitions by creating a folder in the bucket with a version number in the name, and copying the files into it. This code is executed by a CI/CD server agent:
aws s3 sync ./our-project/ s3://our-project-repository/1.0.123/
Promoting a version of a stack definition can be done in different ways. With the S3 bucket, I’ll sometimes have a folder named for the environment, and copy the files for the relevant version into that folder. Again, this code runs from a CI/CD agent:
aws s3 sync — delete \
s3://our-project-repository/1.0.123/ \
s3://our-project-repository/staging/
The pipeline stage for any environment simply runs Terraform (or CloudFormation), grabbing the definitions from the relevant folder.
Running the tool
The commands are pretty much all run by the CI or CD server on an agent. This does a few good things. First, it ensures that the command is fully automated. There’s no relying on “just one” manual step or tweak, which expands with “just one more, for now”. You don’t end up with different people doing things in their own way. You don’t end up with undocumented steps. And you don’t have to worry, in an emergency situation, that someone will forget that crucial step and bork the environment. If there’s a step that can’t easily be automated, then find a way.
Another good thing is that you don’t worry about different people applying changes to the same environment. Nobody applies changes to a common environment by running the tool from their own machine. No need to worry about locking and unlocking. No need to worry about locally edited changes. The only changes made to an environment you care about are the ones that have been fed into the pipeline.
This also helps with consistency. Nobody can make a change that requires a special plugin or utility they’ve installed on their own laptop. There is no tweak that someone made when applying a change to staging, that might be forgotten for production. The tool is always run from a CD agent, which is built and configured consistently, always using the same script, no matter which environment it runs from.
Developer workflow
People working on the infrastructure probably need to make and test changes to stack definitions rapidly, before committing into the pipeline. This is the one place you may want to run the tool locally. But when you do, you’re doing it with your own instance of the environment stack. Pull the latest copy of the definitions from the source repo, run the tool to create the environment, then start making changes. (Write some automated tests, of course, which should also be in the source repo and automatically run in relevant environments in the pipeline.)
When you’re happy, make sure you’ve pulled the latest updates from master, and that your tests pass. Then commit the changes and destroy your environment.
No need to worry about breaking a common environment like staging. If someone else is working on changes that might conflict with yours, you should see them when you pull from master. If the changes merge OK, but cause issues, they should be caught in the first test environment in the pipeline. The build goes red, everyone stops and looks to see what needs to be done to fix it.
When is this appropriate?
I’ve been using pipelines to manage infrastructure for years. It seemed like an obvious way to do it, since ThoughtWorks teams use pipelines for releasing software as a matter of course. But recently I’ve been running across experienced people who maintain separate definition file for each environment.
In some cases I think people simply haven’t been exposed to the idea of using a pipeline for infrastructure. Hence this article. But I’m also aware that these two different approaches (and maybe others I’m not aware of) are appropriate for different contexts.
The pipeline approach has more moving parts than simply having a separate stack definition for each environment. For smaller teams, with a simple release process and not many environments, a pipeline may be overkill. But when you have more people working on a system, and especially when there are multiple teams and roles, a pipeline creates a consistent, reliable process for rolling out infrastructure changes. It may also make sense even for smaller teams who are already using a pipeline for their software to add their infrastructure files into it, rather than having a separate process for environments and applications.
There are some caveats. It takes time to get comfortable with making infrastructure changes using a pipeline. You may not get as much value without at least some degree of automated testing, which is another discipline to build. Running infrastructure management tools automatically from a CD server agent requires a secure approach to managing secrets, to avoid your automation system from becoming an easy attack vector.
Beyond pipelines
The pipeline approach I’ve described answers the question of how to manage multiple instances of a particular environment, in a “path to production”. There are other challenges with managing a complex infrastructure codebase. How do you share code, infrastructure, and/or services between teams? What’s the best way to structure and release modules of shared infrastructure code?
I’ve also spent some time thinking about patterns I’ve seen for splitting a single environment into multiple stacks, which I described in a talk. If this article is about applying principles and practices from Continuous Delivery to infrastructure, that talk was about applying principles from Microservices to infrastructure.
I hope this article gives people food for thought, and would like to hear what other approaches people have tried and found useful.
Acknowledgements
Aside from inspiration from Charity Majors and Yevgeniy Brikman, I received feedback from my ThoughtWorks colleagues Nassos Antoniou, Andrew Langhorn, Pat Downey, Rafael Gomes, Kevin Yeung, and Joe Ray, and also from Antonio Terreno.
This article was originally posted on Medium and on ThoughtWorks Insights.


